CSD lists implementation notes
Link encoding
Links to neighboring list items are stored in intrusive “entry” structures like the one seen below:
struct ListItem {
int i;
csg::tailq_entry<ListItem> e; // Holds links to neighboring list items
};
The term “entry” comes from the original queue(3) library macros, e.g., TAILQ_ENTRY(ListItem) e would be written instead of csg::tailq_entry<ListItem> e. If you look at the definition of csg::tailq_entry however, it is much more complex. That complexity comes from the flexibility to use either offset-based extractors or invocable extractors. As explained in the extractor documentation, offset-based extractors usually result in better code generation but have stricter requirements (they only work with complete standard layout types).
The neighbor links are stored in a different format depending on the type of entry extractor. One additional complexity is that we can declare entry objects without having to specify anything about the entry extractor. Thus, the entry object must be able to work with either format, regardless of which one will eventually be used. Consequently, the “neighbor link” type is a union of two different types, but only one will be used depending on the kind of entry extractor that is eventually specified in the template argument of the tailq_head or tailq_proxy type.
The design is eaiser to understand if we look at both link formats separately first. To make the expostion more concrete, we’ll pick a particular entry type like tailq_entry<ListItem> or slist_entry<ListItem>>, depending on what is shown in the nearest figure.
offset_entry_ref
When using an offset-based entry extractor, CSD stores neighbor links by storing pointers to the neighbors’ entry objects (e.g., pointers to neighboring tailq_entry<ListItem> members) in a special smart pointer called offset_entry_ref – so named because it is a reference to an entry used in the “offset” case. This smart pointer isn’t very smart – it adds almost nothing beyond a plain old tailq_entry<ListItem>*. The reason it is a separate type is only to satisfy the C++ standard’s notion of when it is safe to read from an inactive union member – because an offset_entry_ref lives in a union with invocable_tagged_ref that we discuss next – and there is a “dark corner” in the code where we need reads from the inactive member to work.
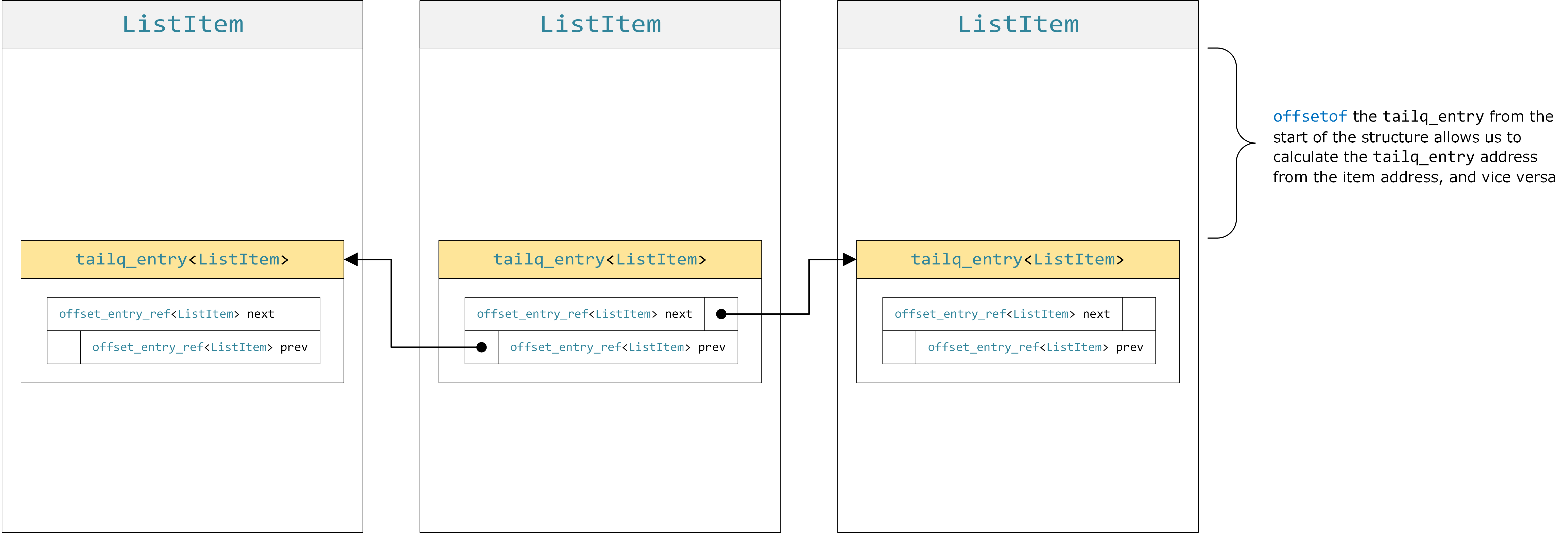
A tailq using an offset-based link encoding. This tends to generate the most efficient code. To reduce clutter, only the links of the middle list item have their arrows shown (click to enlarge).
There is an important symmetry when using the offset link encoding: given a list item of type ListItem, we can get a pointer to the enclosed tailq_entry<ListItem> via simple pointer math, i.e., by adding the offsetof bytes to the base address of the item. We can just as easily go in the reverse direction: given a pointer to a tailq_entry<ListItem>, we can calculate the address of the enclosing ListItem list item by subtracting that same offset. 1
Note that this is different from the way that simple linked lists are written – consider the typical “white board job interview” doubly-linked list:
struct ListItem {
int i;
ListItem *next;
ListItem *prev;
};
The neighbor links in this kind of list point directly to other ListItem instances, not to “entry” member subobjects. What advantages does a separate entry data structure give us?
One advantage is that it allows us to work with special entries that do not live inside ListItems. This functionality is important for both singly-linked and doubly-linked lists, but is easier to illustrate with singly-linked lists.
Consider that STL-style singly-linked lists contain a member function called before_begin, which returns an iterator that points “before” the first item. In the implementation, the list head itself contains an entry, which points to the entry in the first item. An iterator that is pointing before the first item is actually pointing directly to this special entry, as seen in the figure below:
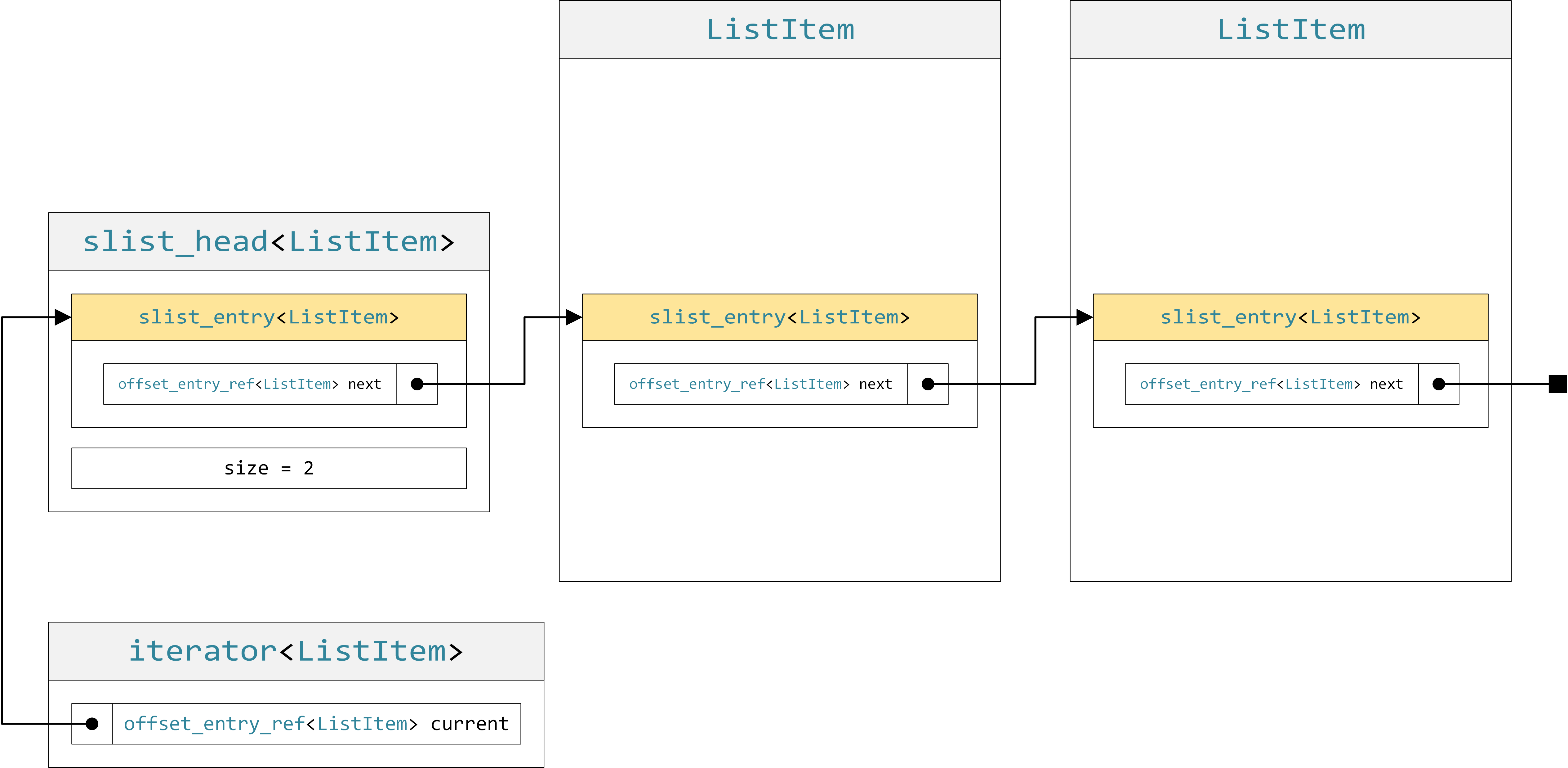
The iterator contains a single offset_entry_ref pointing to the “current entry,” regardless of whether that entry exists inside a list item or exists within the head item (click to enlarge).
This feature is even more critical for the tailq design, which is explained in a later section.
invocable_tagged_ref
Although offset-based link encoding tends to generate the most compact code, it cannot be used with every type. The C++ standard only guarantees that offsetof will work on standard layout types. Since C++17, an implementation may choose to support other types if its class layout strategy can guarantee a fixed offset for that type. In addition to supporting polymorphic classes, there are a number of other advantages to using “invocable” entry extractors, as explained in When to use offset-based extractors.
The invocable link encoding supports the same three features as the offset-based one:
The entry reference type,
invocable_tagged_ref, must be the size of a single pointer.It must be possible to obtain both the list item pointer and the entry pointer from the entry reference type.
It must be able to work with special entries that do not live inside list items.
The invocable_tagged_ref is a single tagged pointer which can point to either a ListItem or directly to an entry (slist_entry<ListItem> in the figure below), depending on the low bit of the pointer. Conceptually, it is a union of a ListItem* and a slist_entry<ListItem>*. If it points to a ListItem, then the enclosed entry can be obtained by invoking the entry extractor, e.g., std::invoke(entryExtractor, *static_cast<ListItem *>(ref)). If it points directly to an slist_entry<ListItem>, then this is one of the “special case” entries that does not live inside an enclosing ListItem.
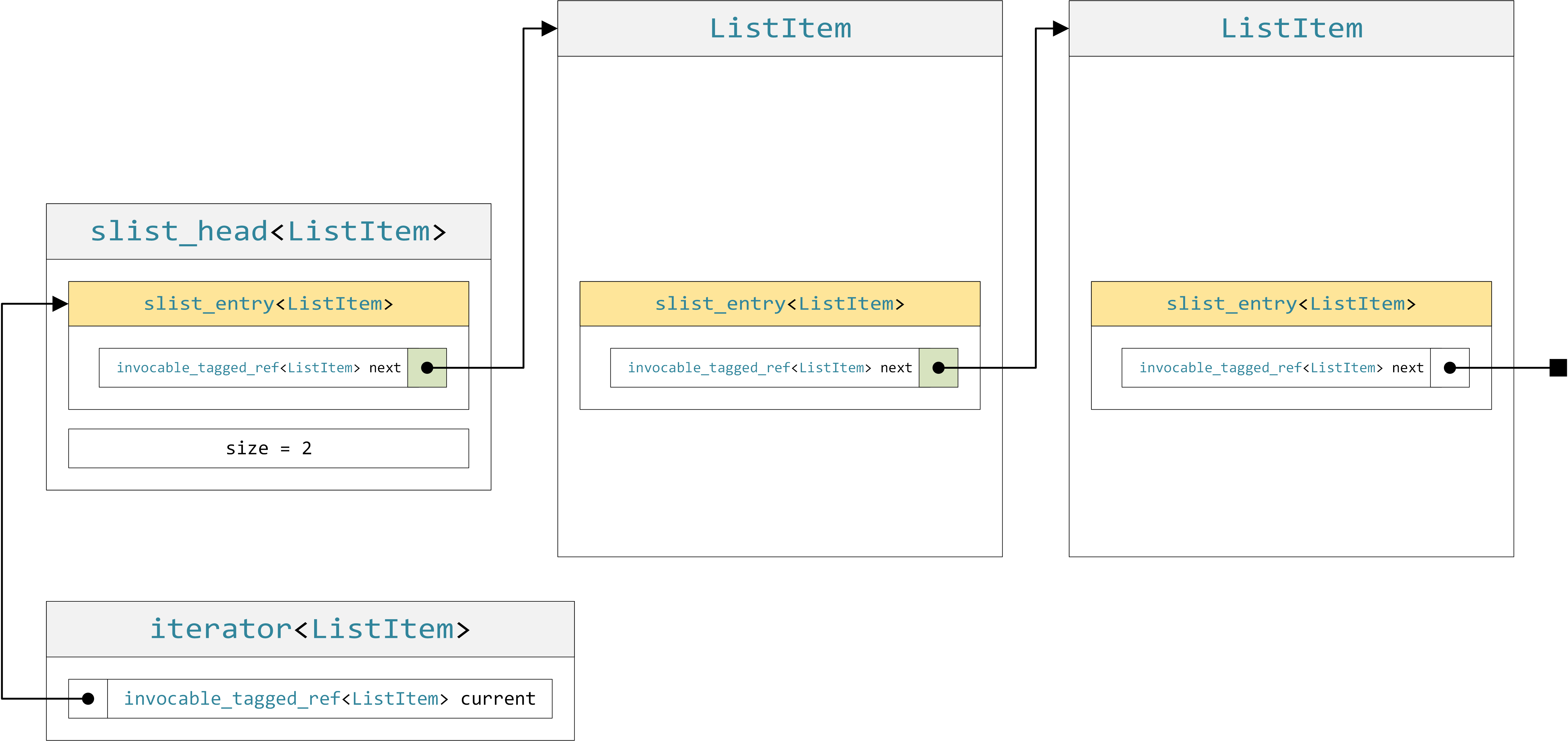
When the pointer is untagged (unshaded), it points directly to an entry_type; when the pointer is tagged (shaded), it points to a ListItem (click to enlarge).
The tag encoding rule is important: note that when the pointer is untagged (i.e., when the LSB is 0), it points directly to an entry_type – exactly as it always does in the case of an offset_entry_ref.
entry_ref_codec and entry_ref_union
CSD orginally used the term “link” but to improve readability, neighbor links are now called “entry refs.” The “ref” part of the name emphasizes that they are not entries themselves, but pointer-like objects that refer to entries. The “entry” part of the name emphasizes that their primary purpose is to refer to structures such as slist_entry<ListItem> – although they also simultaenously refer to the enclosing ListItem when it exists.
entry_ref_codec is a helper traits class that shields the list implementation from having to deal with the differences between offset_entry_ref and invocable_tagged_ref; it provides a partial specialization for each, but gives them a common interface. For example to get an entry, offset_entry_ref does not need to do any additional work, whereas invocable_tagged_ref usually needs to invoke the entry extractor on the ListItem. The entry_ref_codec class offers a static member function (get_entry) which accepts the entry extractor and in the offset case, ignores it, but in the invocable case, uses it to extract the entry.
entry_ref_union is a union of both offset_entry_ref and invocable_tagged_ref – this is the type actually used to store neighbor links in entry structures. As mentioned earlier, a union is needed because we do not want to specify the entry extractor at the time an entry is declared, but the entry extractor determines what encoding will be used. Therefore we must declare a union containing the different encoding types. Once the entry extractor is known, the list head will select the appropriate entry_ref_codec specialization at compile time.
There is one tricky implementation detail regarding entry_ref_union: although the list is usually the only entity that manipulates entries, certain entries (e.g., the one in tailq_fwd_head) must be default-constructed before the extractor is known.
These constructors perform their initialization through the offset_entry_ref member of the union, regardless of which union member will be used by the list. This is safe to do because both offset_entry_ref and invocable_tagged_ref have a common initial sequence – a single std::uintptr_t that holds their respective encodings. In this case, the C++ standard permits reading from a union member that was not used for the write. All subsequent reads and writes after initialization use the correct union member. For consistency, when a write needs to occur prior to knowing which encoding will be used, the write if done through the offset_entry_ref member.
Iterator implementation
List iterators store an entry ref for the “current” entry. As described above, with the help of the entry_ref_codec (and the EntryEx functor, for invocable link encoding), the iterator can access both the entry object and the list item.
The iterator is either the size of a single pointer or two pointers, depending on the EntryEx functor. The iterator stores a special “smart pointer” to the invocable object, csg::compressed_invocable_ref, which (using template partial specialization) is empty if the EntryEx functor is stateless, i.e., if it is both an empty class and is trivially constructible and destructible. This smart pointer is also declared with [[no_unique_address]], so if the extractor is stateless, it will not store anything. This is the common case, because both offset-based and invocable_constant-based functors are stateless.
List design
The singly-linked list design is straight-forward: a head entry points to the first item, and all the intrusive entries point to the next item. The last item has a next value of nullptr (encoded as zero). In the case of stailq, an entry_ref to the last item also stored.
The tailq’s doubly-linked list design is insipred by the std::list implementation in libc++. In this design, the list is actually circular: the tailq_entry in the list head links the two ends of the list, and corresponds to the end() sentinel. 2 Its “previous” link points to the last item in the list, and its “next” item points back around to the first item in the list. This is shown in the figure below, which also illustrates the tagged pointers in the invocable_tagged_ref encoding:
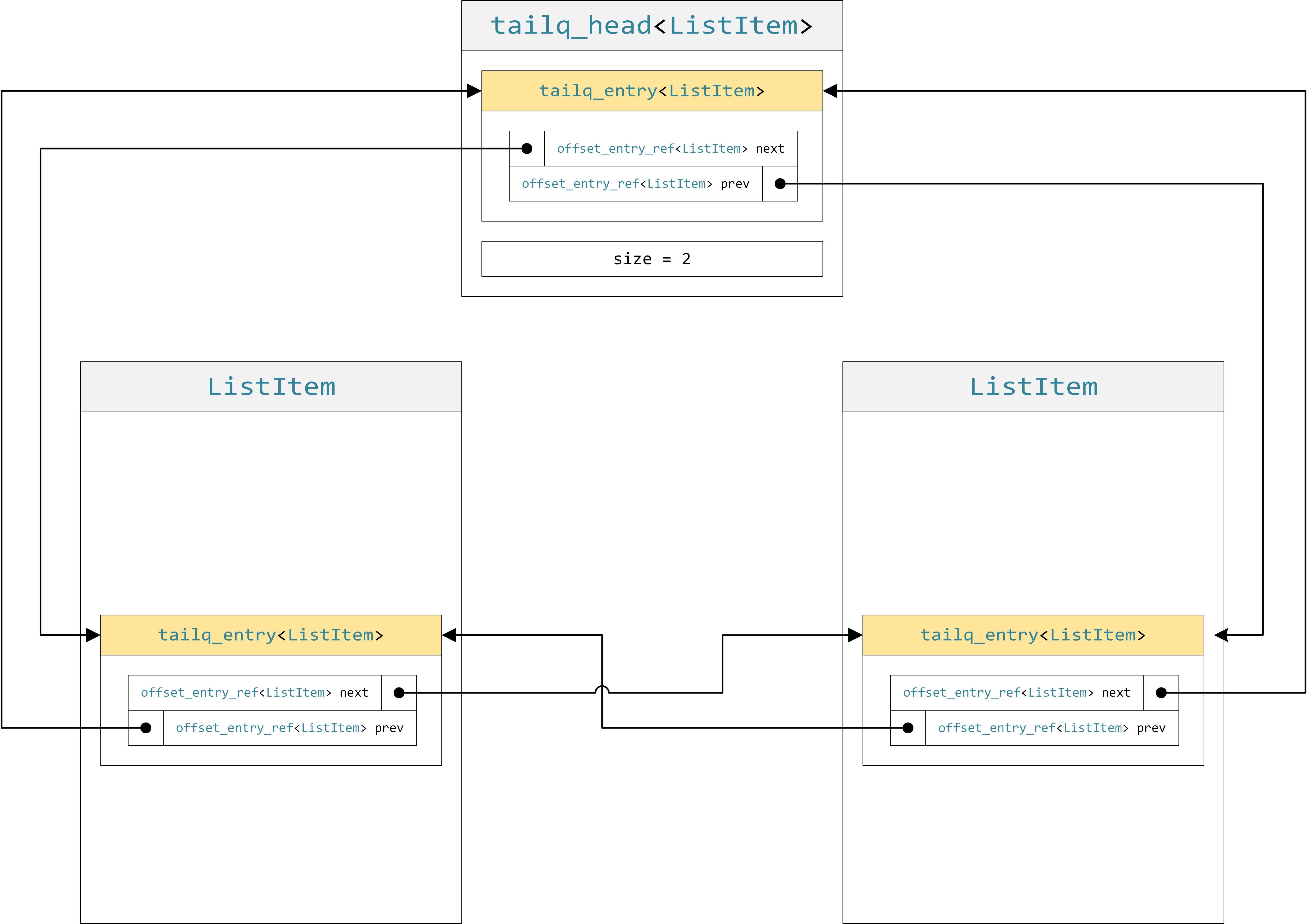
When the list is empty, both links in the head entry point to itself:

This is the ideal design given the STL container requirements, e.g., that *--end() is a valid expression that yields the same value as back(). If you work out how to edit the links to insert and remove items “in the middle” of the list, this same code will work even at the boundary conditions (a list of size 0, size 1, etc.) without any special conditionals that check for those cases.
This interesting property makes the circular doubly-linked list one of the “cleanest” and most “algorithmically satisfying” data structures you’re ever likely to encounter – especially when compared to “white board job interview” linked lists which explicitly use nullptr at the head/tail of the list, and need if statements in almost every function to treat the boundary cases differently.
Miscellaneous Notes
iterator_t and const_iterator_t
Several classes define seemingly superfluous identity type aliases for their iterators, e.g.
class iterator;
class const_iterator;
using iterator_t = std::type_identity_t<iterator>;
using const_iterator_t = std::type_identity_t<const_iterator>;
These are needed to work around a strict policy in clang regarding the use of incomplete types in template class member functions, see this cfe-dev mailing list post for details.
compatible_slist and friends
Although copying list heads is not possible, it is possible to move list heads. The source and destination of the move do not need to have the exact same type. For example, the source list head might not store the list size inline (i.e., its SizeMember is csg::no_size) whereas the destination list head does store the size.
In this sense, certain list head types are compatible with others for the purpose of move construction and assignment. The definition of compatibility is formalized as a concept, e.g., for slists:
template <typename T, typename O>
concept compatible_slist = slist<T> &&
std::same_as<typename T::value_type, typename O::value_type> &&
std::same_as<typename T::entry_extractor_type, typename O::entry_extractor_type>;
Originally the code used other_list_t for compatible list move constructor and move assignment overloads. other_list_t is an alias template which binds the template parameters that have to be same while leaving the others free. If template argument deduction could be carried out against these overloads, then a compatible list would find an available move constructor or move assignment operator.
When support for C++20 ranges was added, the other_list_t-based compatible list constructor overloads started “losing out” to the range constructors during overload resolution: after all, the compatible lists are ranges and thus technically are more constrained. This required “compatible lists” to be formalized as their own concept which is a refinement of (more constrained than) std::ranges::input_range<T>. Note that compatible_slist has slist<T> as its first atomic constraint, which in turn has std::ranges::input_range<T> as its first constraint.
Unusual code formatting convention
The naming of variables, functions, and classes may seem inconsistent: sometimes lower_case_snake_case identifiers are used, other times camelCase (replete with m_ member prefixes) is used. There is a pattern though: implementation details (such as a private member variables) use camelCase, whereas names in public interfaces use lower_case_snake_case. Why is this?
It is because CSD copies LLVM’s style: its normal style is camelCase, but for consistency, it uses the STL formatting rules when implementing STL-compatible containers or “STL-like” helper classes. This is a useful visual indication that the class in question supports the same interface (namely, an iterator-centric interface) as a “normal” STL class. Since almost everything in CSD is designed to be STL compatible, most public interfaces use lower_case_snake_case. Meanwhile, all non-public names use the CSG “house style”, which is a camelCase style similar to LLVM.
Footnotes
- 1
Several popular C codebases contain a special macro that does this “inverse offsetof” operation to obtain the original structure address from one of the members. It is usually spelled
container_of.- 2
This kind of circular linked list is also described in the classic algorithms textbook Introduction to Algorithms (commonly refered to as “CLRS”) in section 10.2, “Sentinels”, when discussing linked lists.